A practical guide for spatial biology researchers, mIF platform users, and lab informatics teams evaluating image management infrastructure
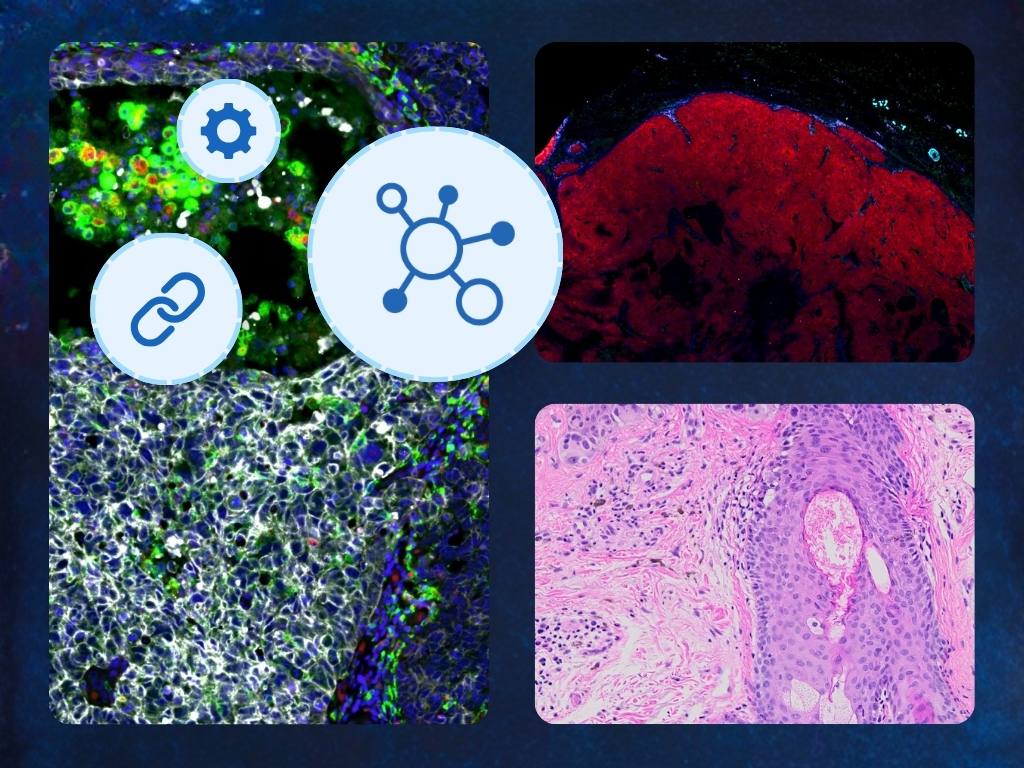
Spatial biology has arrived at an inflection point. Multiplex immunofluorescence platforms can now interrogate dozens — in some cases hundreds — of protein markers simultaneously, at single-cell resolution, across whole tissue sections. The biological insights these datasets unlock are genuinely transformative. The data management challenges they create are equally significant.
A single high-plex mIF image can run from a few to several hundred gigabytes. A study involving multiple slides, multiple panels, and multiple timepoints can quickly reach the terabyte scale. These files don't behave like ordinary image data: they contain dozens of channels, require specialized visualization tools to interpret, and come in proprietary formats that most general-purpose software can't open — let alone stream, organize, and share collaboratively.
The result is a familiar frustration for spatial biology teams: the science is moving faster than the infrastructure supporting it. Researchers are spending time on data logistics — transferring hard drives, managing storage, wrestling with format incompatibilities, waiting for downloads — that should be spent on discovery.
This article is for teams that have felt that frustration, or that want to avoid it. It explains what image management for spatial biology workflows actually requires, where common infrastructure approaches fall short, and what a highly specialized solution looks like in practice.
Why spatial biology breaks conventional image management
The image management challenges of spatial biology are not simply a scaled-up version of conventional digital pathology challenges. They're qualitatively different in ways that matter for infrastructure selection.
File size is orders of magnitude larger. A standard brightfield whole slide image — H&E or IHC — typically runs from a few hundred megabytes to a few gigabytes. A high-plex mIF image routinely exceeds 50–100GB per file. This isn't just a storage capacity problem; it changes what "access" means. You can't download a 100GB file each time you need to review it. Any workflow that involves moving files around — emailing, uploading to shared drives, transferring to analysis systems — becomes impractical at this scale.
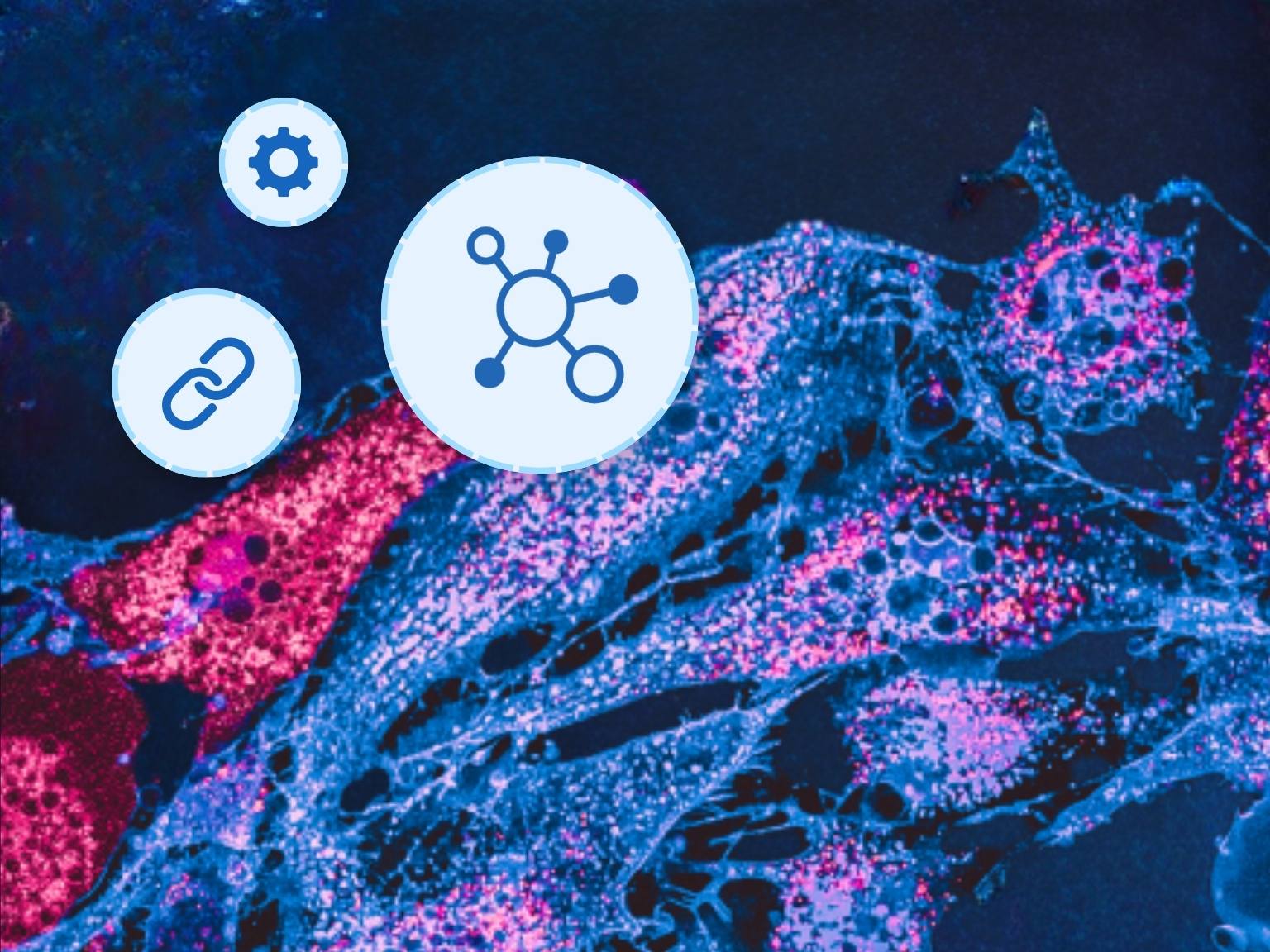
Channels multiply visualization complexity. A brightfield image has three color channels. A multiplexed immunofluorescence image can have 10, 20, 35, or more. Interpreting these images requires the ability to toggle channels on and off, adjust per-channel render settings and histogram controls, overlay combinations of markers, and compare rendering configurations across samples. General-purpose image viewers — and most pathology viewers built for brightfield workflows — don't support this. A viewer that can't handle high-plex visualization isn't a minor inconvenience; it's a barrier to doing the science.
Format fragmentation is acute. Every major multiplex platform — Bio-Techne Spatial (formerly Lunaphore) Quanterix Spatial (formerly Akoya Biosciences), 10x Genomics, Leica, Zeiss, and others — produces images in proprietary formats with their own data structures, compression schemes, and metadata conventions. An image management system that doesn't support your specific scanner's output format is simply not usable for your workflow, regardless of its other capabilities.
Collaboration is harder. When files are hundreds of gigabytes, the conventional approaches to sharing — email attachments, USB drives, file transfer services — are categorically impractical. Even cloud storage platforms like Dropbox or SharePoint, which handle ordinary files reasonably well, struggle with spatial biology data: upload times are prohibitive, download times are worse, and there's no mechanism for streaming or collaborative real-time access. Teams with collaborators at other institutions or CROs with sponsor clients are particularly exposed to this friction.
Analysis integration is more complex. Spatial biology workflows typically involve image analysis — cell segmentation, marker quantification, phenotyping — that requires connecting the IMS to external analysis platforms. The annotation data produced during that analysis, and the results returned to the IMS, need to be preserved alongside the original images in a format that supports downstream interpretation and reproducibility.
Where conventional image storage approaches fall short
Most spatial biology teams arrive at a dedicated IMS after working through a progression of inadequate alternatives. Understanding where each approach breaks down is useful both for teams still on that journey and for those building the business case to upgrade.
Personal and local storage (USB, HDD, local workstation) reaches its ceiling almost immediately at spatial biology scale. Files of 50–100GB are manageable one at a time on a local drive, but there's no path to team collaboration, no remote access, and no practical way to manage a growing library of studies. This is a starting point, not a solution.
Corporate network storage (NAS, SAN) solves the team access problem but introduces new constraints. Remote access typically requires VPN, which adds friction and degrades performance for large file access. Storage capacity can become a budget and procurement issue. And NAS/SAN systems have no pathology-specific organization or visualization capabilities — the image data is accessible, but not in any way that supports the actual review workflow.
Corporate file sharing platforms (Dropbox, SharePoint, Box) are familiar and easy to deploy, but they're designed for documents and ordinary media files, not for whole slide images. Upload and download times for large mIF files are prohibitive. Size of files being uploaded are often too restrictive. There's no browser-based streaming viewer — every review session starts with a download. There's no concept of channels, render settings, or the spatial biology metadata that gives images their scientific context. These platforms are a collaboration solution for a different kind of file.
Raw cloud storage (AWS S3, Azure Blob) provides unlimited scalable storage at reasonable cost, but requires significant IT and development resources to deploy, secure, and maintain. More importantly, cloud object storage is not an image management system — it's a storage layer. Building the viewer, the access controls, the collaboration tools, and the analysis integrations on top of it is a substantial engineering project, and maintaining that infrastructure is an ongoing obligation. This is the build-vs-buy question applied specifically to spatial biology, and the conclusion is the same: purpose-built commercial infrastructure almost always delivers better outcomes than DIY cloud deployments for this use case.
→ For a full treatment of the build-vs-buy question, see: Should You Build or Buy Your Digital Pathology IMS?
The common thread across all of these approaches is the same: they were designed for something other than spatial biology workflows, and the gaps show up exactly where spatial biology makes the most distinctive demands — file size, channel complexity, format support, and collaborative access.
What a specialized spatial biology IMS provides
An image management system designed for spatial biology workflows addresses these challenges not through workarounds, but through architecture. The capabilities that matter most:
High-performance streaming for large files
Browser-based image streaming — delivering high-resolution image data to a web viewer without requiring the user to download the file — is the foundational capability that makes everything else possible. Without it, every review session starts with a transfer that takes minutes at best and hours at spatial biology scale. With it, images load instantly, users can zoom and pan fluidly regardless of file size, and the physical location of the data becomes irrelevant to the review experience.
This sounds straightforward, but it isn't: streaming whole slide images efficiently, maintaining performance under concurrent multi-user load, and handling the specific characteristics of high-plex mIF data requires specialized infrastructure. General-purpose streaming approaches that work for video or standard images don't translate to gigantic pyramidal tile structures with dozens of channels.
A viewer built for high-plex data
Visualizing multiplexed immunofluorescence data requires viewer capabilities that go well beyond what brightfield pathology demands:
- Unlimited channel support — the ability to display and manipulate any number of fluorescence channels without hitting a platform ceiling
- Per-channel histogram controls — intuitive tools for adjusting intensity ranges, threshold settings, and color assignments per channel, enabling differentiation of true signal from background noise
- Render settings that can be saved and shared — the ability to lock in a visualization configuration and share it with collaborators, ensuring that everyone is interpreting images with the same rendering baseline. This is not a convenience feature; it's a reproducibility requirement
- Side-by-side comparison — the ability to open multiple images simultaneously and compare rendering configurations, tissue regions, or timepoints within a single session
- Multi-platform image format support — native support for proprietary formats from the major multiplex scanning platforms, without requiring format conversion steps that add time and introduce quality risk
Scalable, cost-intelligent storage
At spatial biology scale, storage economics matter significantly. A platform that charges general-purpose cloud storage rates for petabytes of high-plex image data creates a long-term cost burden that can constrain the scope of research or force premature data deletion decisions.
Hierarchical storage management (HSM) — the automatic movement of data between storage tiers based on access patterns — is the mechanism that makes spatial biology storage economically sustainable at scale. Frequently accessed, active datasets are maintained on high-performance storage tiers for fast retrieval. Older or less-accessed data is automatically migrated to lower-cost archival tiers without sacrificing accessibility — when you need a file from two years ago, it's retrievable on demand, not after a lengthy restoration process.
The practical result: storage costs that scale intelligently with data volume and access patterns, rather than linearly with total data size. At petabyte scale, the difference is substantial.

→ Learn more about PathcoreFlow's hierarchical storage management and how it offers affordable archival solutions for spatial biology.
Collaboration without file transfer
The right approach to spatial biology collaboration is not moving data to people — it's giving people access to data. An IMS with browser-based access and granular permission controls lets you share images with external collaborators, CRO clients, or scientific advisors by granting access to the platform — not by transferring files. Collaborators access images through a browser from any device, without installing specialized software, without downloading multi-gigabyte files, and without requiring your IT team to set up VPN access or manage external accounts.
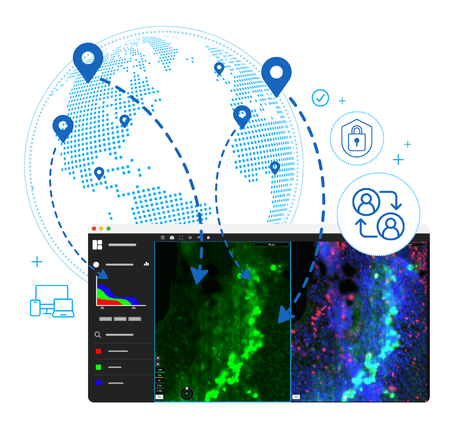
Access can be granted and revoked at any time. Viewing and annotation activity is logged. The data never leaves the controlled environment. This model is both more secure and dramatically more practical than file-based sharing — and it scales to any number of collaborators without the logistical complexity of file distribution.
Analysis platform integration
Spatial biology workflows don't end at image review — they extend into quantitative analysis: cell segmentation, phenotyping, spatial statistics, and increasingly, AI-driven pattern recognition. The IMS needs to connect to the analysis platforms where this work happens, and it needs to do so in a way that keeps image data, analysis results, and annotations in a single organized environment.
This means open APIs and validated integrations with the analysis tools spatial biology teams actually use — commercial platforms like Visiopharm, as well as custom or in-house solutions. It also means that annotations created in the IMS during review can feed analysis model training, and that results returned from analysis tools are stored and displayed alongside the original images for interpretation and reporting.

Vendor-agnostic integration is the key principle: as new analysis tools emerge and as spatial biology platforms evolve, the IMS should accommodate change without requiring infrastructure rebuilds.
The reproducibility dimension: render settings matter more than you might think
One of the less-discussed but practically significant challenges in spatial biology data management is rendering consistency — ensuring that when two researchers look at the same image, they're seeing the same thing.
Multiplex immunofluorescence images don't have a single "correct" rendering. Channel intensity ranges, color assignments, and threshold settings are all user-adjustable, and different settings can yield meaningfully different visual interpretations of the same underlying data. When collaborators review images independently, without a shared rendering baseline, the resulting discussions can be complicated by differences in what each person is actually seeing — not differences in the biology.
The ability to save rendering configurations and share them with collaborators — so that everyone opens an image with the same channel settings applied — is a direct solution to this problem. It's a feature with implications not just for convenience but for scientific rigor: consistent visualization is a component of reproducible analysis, and in studies that involve multiple reviewers or regulatory submission, that consistency matters.
Questions to ask when evaluating an IMS for spatial biology
Beyond the general IMS evaluation criteria covered in our evaluation checklist, spatial biology workflows warrant specific scrutiny in a few areas:
→ For the complete evaluation framework, see: The IMS Evaluation Checklist: What to Ask Before You Buy
The cost of the status quo
The spatial biology teams that have moved to specialized IMS infrastructure consistently describe the same shift: a significant reduction in the time and energy spent on data logistics, and a corresponding increase in the time available for actual science.
That's not a small thing. In a research environment where the datasets are growing faster than the tools to manage them, the infrastructure decision directly determines how much of the team's capability is available for discovery versus overhead.
The alternative — managing spatial biology data on general-purpose storage and sharing platforms — works until it doesn't, and the point at which it stops working tends to arrive at the worst possible moment: mid-study, when a collaborator needs access to a 100GB file by tomorrow, or when a reviewer needs to compare render settings across a panel and there's no shared configuration to reference.
Digital pathology infrastructure for spatial biology isn't a luxury for large well-funded teams. It's the practical prerequisite for doing the work efficiently — at any scale where the data has started to create friction.
Ready to see PathcoreFlow's spatial biology capabilities in action?
Talk to a solutions expert →
Explore PathcoreFlow for Spatial Biology & mIF →
This article is part of Pathcore's digital pathology resource hub. For related reading, see:
- Everything to Know About an Image Management System (IMS)
- Why Your IMS Choice Defines Your Digital Pathology Strategy
- Should You Build or Buy Your Digital Pathology IMS?
- Overcoming the Bottlenecks in Spatial Biology Imaging
- PathcoreFlow 4.0: Enhancing Multiplex IF Imaging Workflows